

I have primarily focused my work on semantic indexing in the domain of Greek literature. Specifically, I have placed emphasis on developing a deep learning architecture for text classification, taking Genre/Form terms into account. This endeavor brought forth distinct challenges, largely arising from the use of archaic Greek language and the varying quality of the source text, which was frequently impacted by OCR applied to digital books. ECARLE website





Question Answering in Biomedical Domain
Big Projects
- Created By: Dimitris Dimitriadis
- Date: 01/02/2019
- Categories: Big Projects
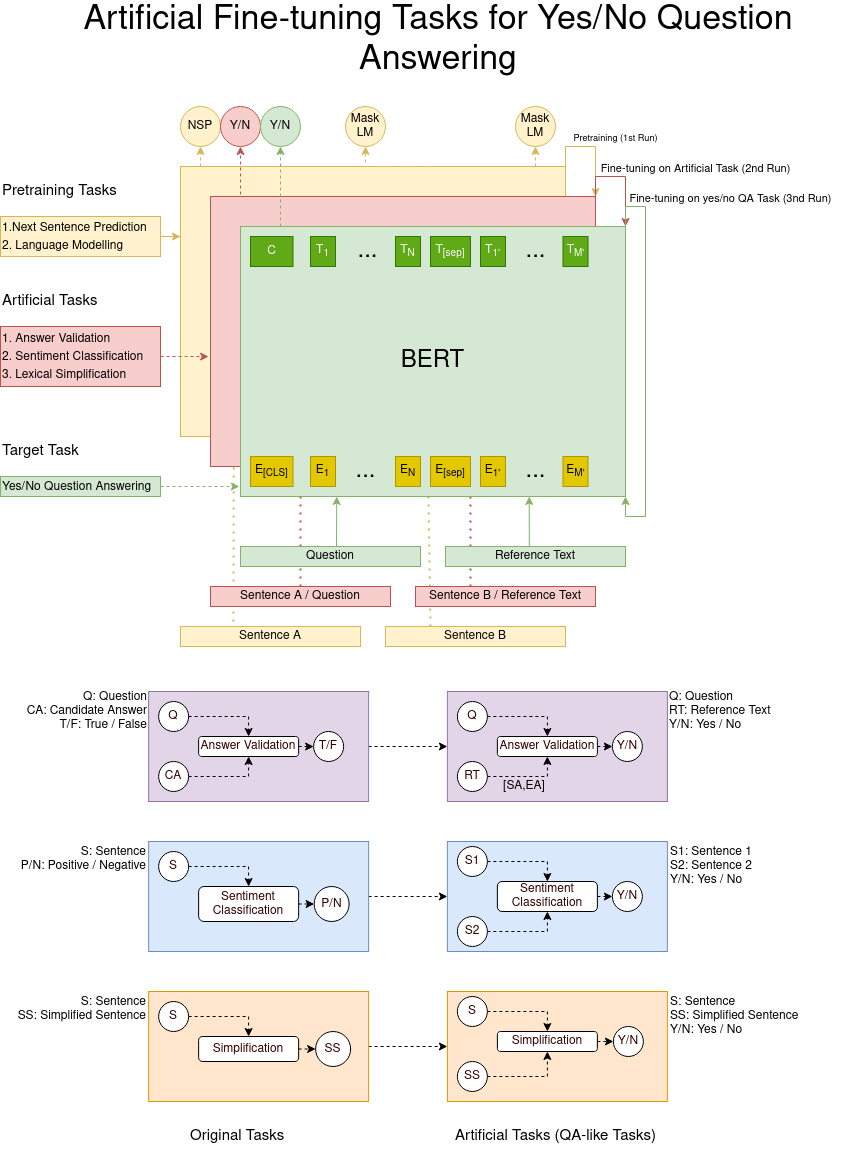
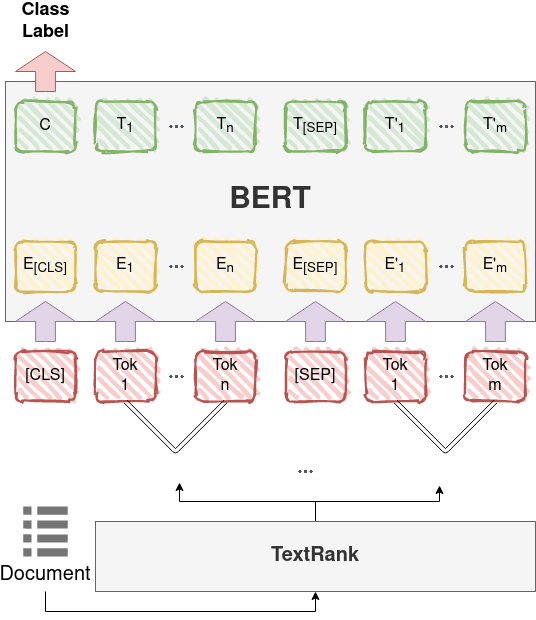
This work is part of the Large Scale Semantic Indexing and Question Answering project. Particularly, user poses a question and the system returns the top 10 related biomedical documents, top 10 passages that probably contain the answer and finally the most relevant answer. The system recognizes the type of the question (factoid or yes/no). Factoid QA component is a learning model on top of the Bert (language representation) while the Yes/No QA component is a learning model that incorporates sentiment information and ELMo embeddings.



